A two-stage recommendation system trained on real Steam data. Given a user’s play history, it retrieves and ranks personalised game recommendations from a catalogue of 8,400 titles.
The demo above shows it in action — pick a user, get recommendations in about 5-15ms.
How Inference Works
When a request comes in, two things happen in sequence:
Retrieval — The user’s play history gets encoded into a 128-dimensional vector. The vector gets compared against pre-computed embeddings for every game in the catalogue via dot product. The top 200 most similar games become candidates. This whole step takes about 2ms because the game embeddings are computed once at startup and cached.
Ranking — Those 200 candidates get re-ranked using richer features. Things like: has the user bought from this developer before? How much do the game’s tags overlap with what they’ve played? The ranking model (XGBoost) scores all candidates and returns the top 12.
Total latency is around 5-15ms. Fast enough that you don’t notice it.


Training Pipeline
The training infrastructure is where most of the main engineering happened. It’s one thing to train a model in a notebook but another to have reproducible pipelines with proper versioning and monitoring.
Data flows through S3 — Raw data gets processed into versioned datasets, which feeds into the feature pipeline, which feeds into model training. Each stage is versioned independently, so I could trace exactly which data produced which model.
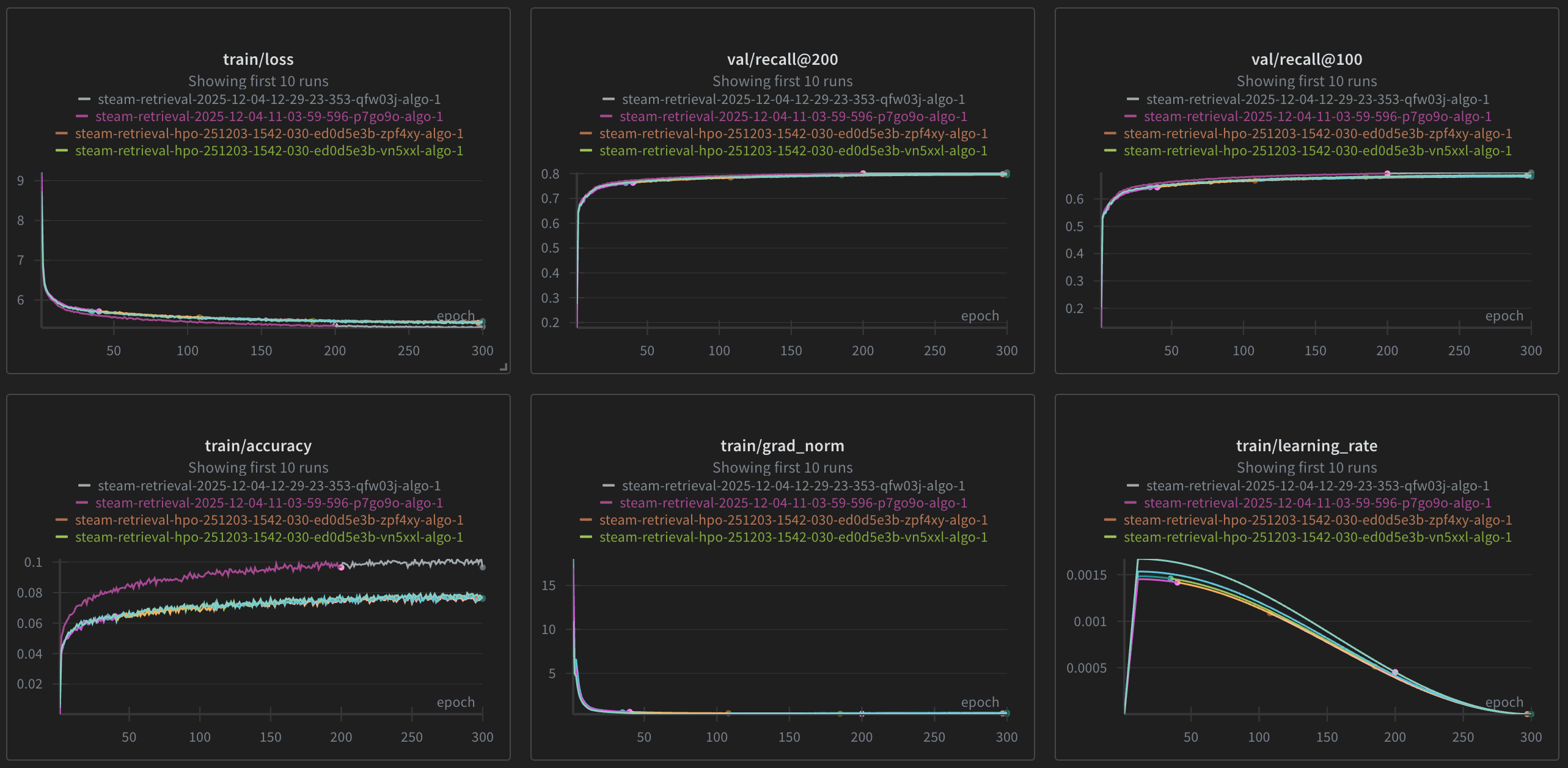
The retrieval model was trained on SageMaker. It needs GPUs as the model computes a softmax over all 8,400 games every single batch. I used A10G spot instances. This GPU also supports mixed precision training and torch.compile, which I was eager to use.
Hyperparameter Tuning ran through SageMaker’s built-in HPO — 30 trials of Bayesian optimisation searching over learning rate, batch size, embedding dimensions and temperature. The tuner optimised for validation Recall@200.


The ranking model trains locally. XGBoost is fast enough on CPU that spinning up cloud infra would’ve been overkill. I used Optuna for hyperparameter search here.
Everything lands in a model registry on S3 - versioned model weights, training configs, and eval metrics. Each run gets tagged with its W&B run ID so I can pull up the full training history later.
Infrastructure is managed with Terraform - the S3 buckets, IAM roles and permissions are all defined as code rather than clicked through the console.
The Models
Retrieval: Two-Tower
The retrieval model uses a two-tower architecture — one neural network encodes users, another encodes games, and similarity is just a dot product between their outputs.
The item tower takes everything I know about a game:
- A learnable embedding for game ID itself
- Genre, tag, and spec embeddings (pooled across multiple values)
- Developer embedding
- Normalised price
All of that gets concatenated and projected down to 128 dimensions.
The user tower is simpler — it encodes the user’s play history by averaging the item embeddings of games they’ve played, then projects that down to 128 dimensions.
Training uses global softmax over the entire catalogue rather than sampled negatives. This matters a lot for smaller catalogues — with only 8,400 games, standard negative sampling techniques break down because a user’s own games keep appearing as “negatives” in other users’ batches. Using the full catalogue as negatives avoids this entirely.
Ranking: XGBoost
The ranking model takes the 200 candidates from retrieval and reorders them using 14 features:
| Type | Features |
|---|---|
| Context | Retrieval score from two-tower model |
| User-Item | Developer affinity, publisher affinity, genre overlap, tag overlap, playtime-weighted affinities |
| Item | Price, release year, sentiment, multiplayer flag |
| User | Average price of owned games, total playtime, games owned |
Developer affinity turned out to be surprisingly powerful — users strongly prefer buying from developers they’ve purchased from before. Adding that single feature gave a significant bump in ranking quality.
Results
| Stage | Metric | Value |
|---|---|---|
| Retrieval | Recall@200 | 81% |
| Retrieval | NDCG@10 | 0.135 |
| After Ranking | NDCG@10 | 0.451 |
The ranking model nearly triples NDCG compared to using retrieval scores alone. That’s a 200%+ lift — which makes sense, since the ranker has access to much richer features than the retrieval model.
Stack
| Layer | Tech |
|---|---|
| Training | PyTorch, XGBoost, SageMaker (spot instances) |
| Tuning | SageMaker HPO, Optuna |
| Tracking | Weights & Biases |
| Data | Pandas, Parquet, S3 |
| Infrastructure | Terraform, IAM, SSM Parameter Store |
| Serving | FastAPI |
| Frontend | HTML/CSS/JS |